.png.b65a310adf7c076fa39cc70a3ec91c19.png)
Mr. Fox
-
Posts
6,591 -
Joined
-
Days Won
790
Content Type
Profiles
Forums
Events
Everything posted by Mr. Fox
-
.thumb.png.362386d2804d5f9fbcf2ec7f5aa009c5.png)
*Official Benchmark Thread* - Post it here or it didn't happen :D
Mr. Fox replied to Mr. Fox's topic in Desktop Hardware
I just watched that video and hour or two ago and Jay is making a lot of sense. I wouldn't want a 4080, but it would make more sense to buy a 4080 than a new 3080 or 3090 if I were going to waste a large sum of money on an overpriced GPU. Though it is not particularly desirable, it is the only one that makes any sense right now even though it is grossly overpriced. Sad days we're living in right now. Totally nuts. -
*Official Benchmark Thread* - Post it here or it didn't happen :D
Mr. Fox replied to Mr. Fox's topic in Desktop Hardware
-
The whole idea is to force the purchase of new hardware and forcing adoption of a trashy crap operating system. It has nothing to do with compatibility or capacity with hardware and everything to do with greed and making computer technology a totalitarian digital ecosystem. The world's technology leaders are filthy scumbags. I wish for tragedy, destruction and financial ruin to visit all of them.
-
*Official Benchmark Thread* - Post it here or it didn't happen :D
Mr. Fox replied to Mr. Fox's topic in Desktop Hardware
I hate having to admit it when this guy is right, but when someone states the truth I have to support it. Right is right no matter whose mouth the words emanate from. AMD is not in the game to win. They never have been. Or, at least they don't behave as if they are. Maybe they don't know how because they haven't won at anything except being the low cost leader since about 2003. -
*Official Benchmark Thread* - Post it here or it didn't happen :D
Mr. Fox replied to Mr. Fox's topic in Desktop Hardware
If I had a 3D printer and knew how to use it (or a CNC machine - even better) I would make a direct die frame that is made like the IHS frame but thinner on top. I think if you glue the cold plate in place with a drop of Super Glue on each side in the center, the danger of knocking off the SMDs will be minimized. Latching the cold plate down using the Intel ILM sucks and I think that method carries greater risk if it is not held in place. I think it would be safer to do direct die by using Kapton tape to hold the CPU in the socket and just set an ordinary waterblock on the die. Then the chances of knocking off the SMDs is slim. If their warranty service were like EVGA I would be more forgiving of their shoddy QC. Although, I have not forgiven them yet for killing the best 10900KF sample I have ever owned. Probably won't. When they sell you a pile of trash and it takes more than a month to resolve the matter that is unacceptable. When you buy their top of the line products you should get a cross-ship RMA and next business day exchange service. (Not overnight air, but shipped by next business day.) You have to pay to ship their broken garbage to them, wait for them to receive it, then get in line for testing and then wait for them to decide whether to make excuses why it is your fault instead of theirs and the wait for them to determine whether they are going to repair it or replace it, then wait for them to act on their decision. It is an absolute JOKE and I'd like to see them crucified for it. The Rampage board I had that caught on fire was obviously destroyed and it took the idiots 6 weeks to ship a replacement. About 10 days was lost waiting for an engineer to examine it to verify they could not repair it. It was obvious at a glance it was damaged beyond feasible repair. Even if they could have done something it was cosmetically destroyed. Within a matter of about three days the Rampage was replaced by an X299 Dark and I sold the refurbished turd they sent as a replacement almost 2 months after it failed. I never even unwrapped it. It went up for sale on eBay immediately. I am not confident that MSI or Gigabutt are actually any different when it comes to shoddy service, and I believe ASSrock might be as bad or worse than ASUS. Maybe Brother @johnkssscan speak to how his experience has been, but as an outside observer I was most definitely not impressed by what I think I saw his experience look like with MSI. When my first Unify-X was failing (it was only a few days old) I was fortunate because it was within the 30 day window for return at NewEgg, so I had them swap it out. Even NewEgg has been service than ASUS. If you buy a good product that is durable you do not need quality warranty service and support. Unfortunately, it is difficult to find good products that live up to my expectations as an overclocking enthusiast. I would consider a Z790 Apex if it were not so grossly overpriced and I had a spare motherboard to use if it failed (which is likely, unfortunately). I believe it is only available in white and I think it leaves a lot to be desired in terms of aesthetics. Black would have been a more logical choice. I know some people like white components, but it really limits their target market. -
*Official Benchmark Thread* - Post it here or it didn't happen :D
Mr. Fox replied to Mr. Fox's topic in Desktop Hardware
More tacky-looking computer crap... LOL. This time from ASUS, not Yeston. They are focusing on this stupid stuff instead of QC. At least it is not effeminate anime crap. https://www.amazon.com/dp/B0B1PG1C8D?ref_=posts -
*Official Benchmark Thread* - Post it here or it didn't happen :D
Mr. Fox replied to Mr. Fox's topic in Desktop Hardware
I find it difficult to imagine why anyone would buy an Alienware or a Razer desktop. The only plausible explanation for it is abject ignorance. Nobody of ordinary intelligence would deliberately waste their money on the rubbish produced by either of these companies, so ignorance is the only way to explain such irrational behavior. -
*Official Benchmark Thread* - Post it here or it didn't happen :D
Mr. Fox replied to Mr. Fox's topic in Desktop Hardware
https://forums.tomshardware.com/threads/alienware-aurora-r15-review-playing-it-cooler.3789545/#post-22887289
-
*Official Benchmark Thread* - Post it here or it didn't happen :D
Mr. Fox replied to Mr. Fox's topic in Desktop Hardware
You must have stood too close to me and my crummy product sample kooties jumped over onto you. Asus reliability is extremely sketchy on their flagship products. I have had nothing but trouble with Rampage, Maximus Hero and Apex motherboards. What is really goofy is the fact that I have had no problems with their cost-conscious options like Prime and Strix motherboards. It makes no sense, because the opposite should be true. You pay a premium price, but do not get a premium product or premium support for it. This is terribly unfortunate because their enthusiast motherboards have very compelling features and offer performance that is only matched in an EVGA Dark motherboard, but the failure rate and horrible customer service and inconvenience you have to endure isn't a good trade-off for those features. EVGA isn't perfect, but their support and customer-care standards make me always give preference to them over any other brand. Their products are overbuilt and if something goes wrong they swiftly remedy the problem in a hassle-free manner. They don't treat you like a criminal or automatically assume it is the customer's fault and make you wait 3 to 6 weeks to get a replacement. Nobody else does that. The way EVGA operates should be status quo and taken for granted on flagship products no matter what the brand is. -
In my opinion that is a conditioned response because of the numbness of thought the left's droning over utter baloney has created. I think the material they are reporting on is slanted that way, not necessarily the people presenting it. The people presenting it are conservative and more reliably report unvarnished info rather than spin on an agenda, and sometimes the unvarnish truth is offensive. (TBH I always find the liberal woke agenda offensive, on top of being a misrepresentation of info, LOL.) The Ukrainian government is far from what I would view as righteous or angelic, but they're not nearly as messed up as Russian government. Information needs to be reported accurately even when we don't like what we see and hear, or find it offensive or immoral, or seemingly hateful. The mainstream news outlets are never straight about anything with their viewers or listeners. Everything they do is geared toward opinion control and manipulation.
-
*Official Benchmark Thread* - Post it here or it didn't happen :D
Mr. Fox replied to Mr. Fox's topic in Desktop Hardware
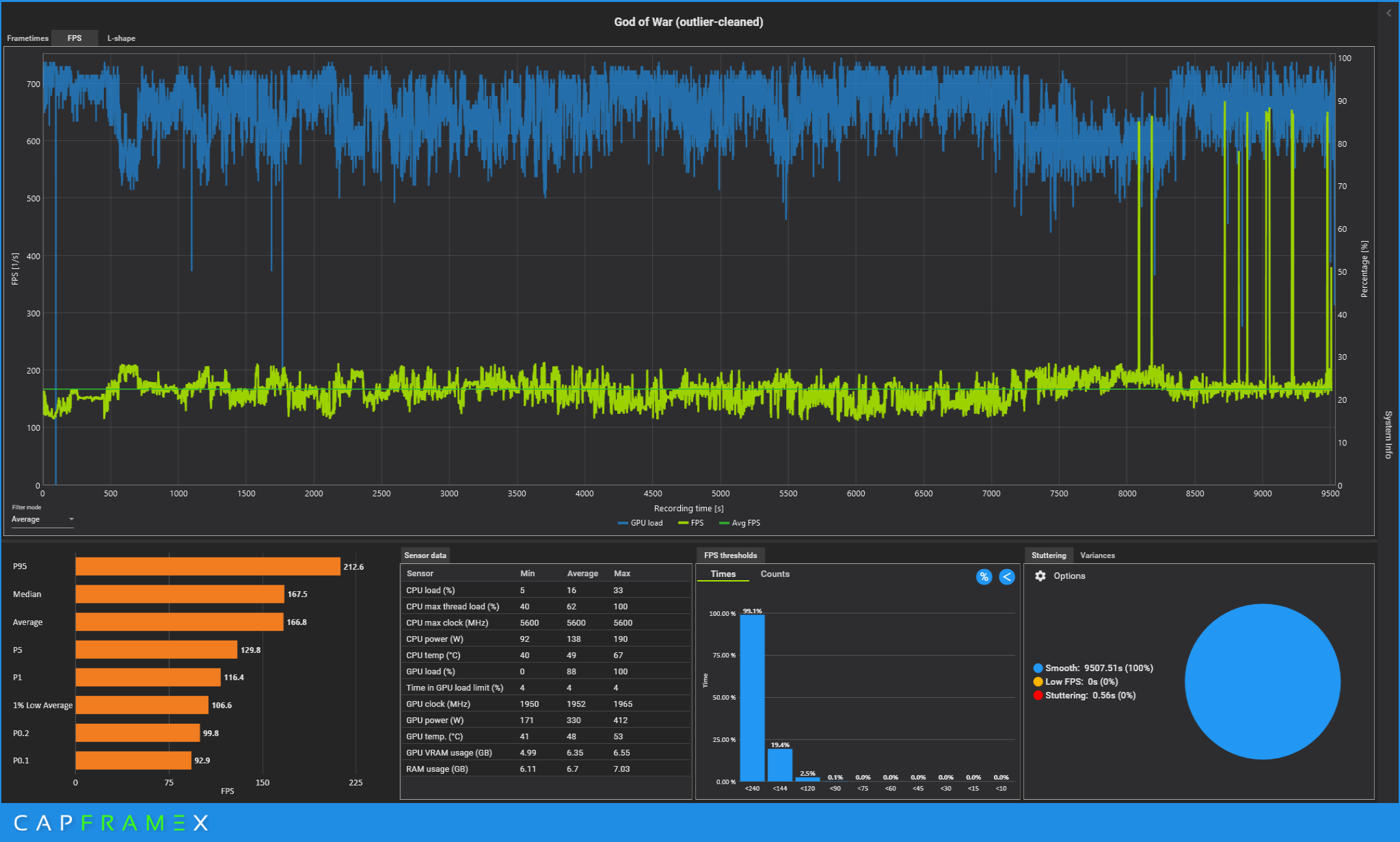
Hey Brother @ryan Glad you got your laptop back, buddy. Here is something you might find useful for the benchmarking. https://www.capframex.com/ Does a great job of measuring system behavior and performance and has a nice overlay.
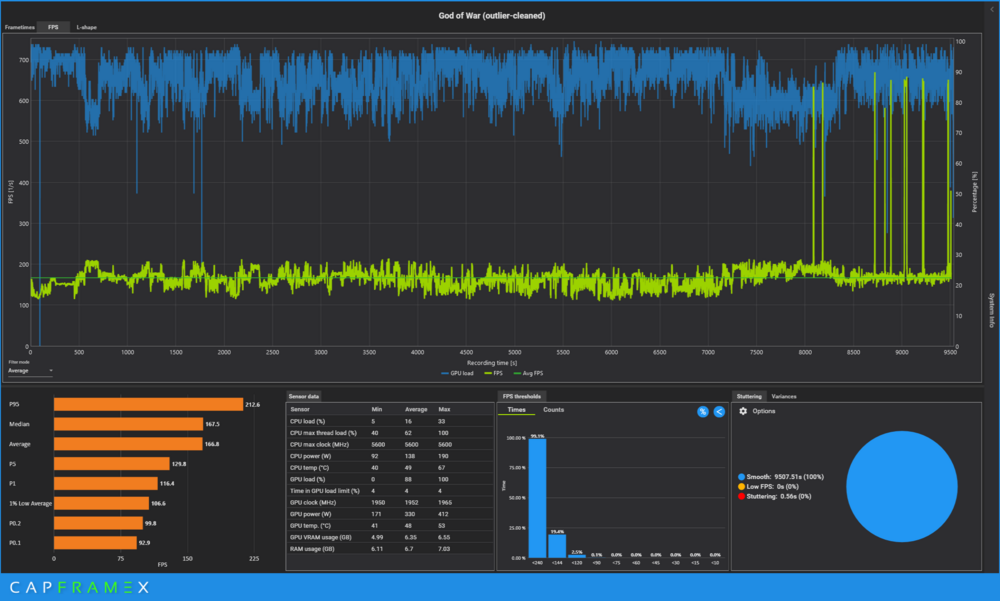

-
-
*Official Benchmark Thread* - Post it here or it didn't happen :D
Mr. Fox replied to Mr. Fox's topic in Desktop Hardware
LOL, I just saw that in another forum. Crazy stuff. https://hwbot.org/submission/5148862_elmor_cpu_frequency_core_i9_13900k_(8p)_9008.82_mhz @electrosoftI missed the comment about you being under the weather. I hope you get well soon and have no sickness in your house over Christmas. Will keep you and the fam in my prayers, bud. -
*Official Benchmark Thread* - Post it here or it didn't happen :D
Mr. Fox replied to Mr. Fox's topic in Desktop Hardware
This is too good to not share it here. Check this out. Never have seen or heard of this before. -
Now this is really crazy. I am definitely going to explore this the next time I need to fix something that is broken.
-
Sorry, I have no interest in buying an overpriced eunuch turdbook. Mobile computing in general no longer interests me, and I hate wasting my money on half-assed garbage. And, that's what all of them are.
-
*Official Benchmark Thread* - Post it here or it didn't happen :D
Mr. Fox replied to Mr. Fox's topic in Desktop Hardware
Yeah I watched that video right after Roman released it. There's almost no need for M.2 heatsinks on modern motherboards. Most motherboards incorporate a better native solution and some of the weird aftermarket alternatives present fitment and aesthetic issues nobody wants to deal with. This generation is a really good one to do nothing if you already have a strong performing 3090/Ti or 3080 Ti, or grab one at the lowest price ever, or go Intel A770 and save a crap-ton of money waiting for something good to surface in a year or two that isn't grossly overpriced, mediocre or prone to self-destruction. I don't see anything from the red or green teams that is worth buying. The only respectable options are absurdly overpriced and have engineering defects that are inexcusable for flagship products. Being greedy and half-assed deserves a 1 or 2 year time-out. They need an uncomfortable and costly pause to think about their behavior and come up with a better strategy that is worthy of our patronage. -
Hmm. Weird, I didn't get that at all. Seemed more biased toward Russia to me. Not really anti-anything, just information about what is taking place.
-
*Official Benchmark Thread* - Post it here or it didn't happen :D
Mr. Fox replied to Mr. Fox's topic in Desktop Hardware
They seem to enjoy being part of the problem rather than part of the solution. Supporting trashmasters like Alienware seems to be their new calling. GIGO... no other way to describe it. Bad input creates bad output. Gee, thanks, Tom's Hardware. *sarcasm* -
Just discovered this chic and like her content. It's a bit dry, but she is really level-headed. Subbed to her channel. Glad I saw this. I have been a fan of the CoD franchise and was looking forward to acquiring the new Modern Warfare, but there is no way I will consider it after seeing the filth and controversy it is promoting. Welp... no more support for anyone on Patreon from this fellow. May they burn in hell for eternity. Exploitation of children and supporting, even protecting, those that do is just going too far.
-
-
The reason is because they are a wicked company, lead by fundamentally dishonest people that are driven by nefarious intentions that ultimately provide no legitimate benefit to the people that use their latest operating system digital abortion.
-
*Official Benchmark Thread* - Post it here or it didn't happen :D
Mr. Fox replied to Mr. Fox's topic in Desktop Hardware
It works well. Once in a great while I tinker with it. I think I have used my Steam Link two or three times this year just for shiggles and it is pretty darned impressive. I hate using my XBOX Elite wireless controller (or any gamepad for that matter) for most games though and my only opportunities to use the 4K TV set for this are when I am the only one home. My preference is to sit at the keyboard/mouse in front of my computer, but the capabilities are impressive and the benefits (or pleasure) some folks will derive from it are self-evident. I believe a wireless keyboard and mouse combo with a unified USB receiver will also work with the Steam Link instead of my gamepad controller, but I don't want to spend money on that to find out since I so seldom use it and would not use them otherwise. I paid less than $10 each for two brand new Steam Link devices during a Steam Christmas sale a few years ago and gave one to @Premaas a gift. I cannot imagine that they would actually expect anyone to pay for this. Maybe they don't and it is their way of getting rid of it organically because they are no longer interested in supporting it. It probably isn't a cash cow for them so they stopped caring. -
I agree. The biggest issue is the illegal entry, lawlessness and politically motivated agenda driving the lawlessness under a pretentious facade of fake woke humanitarianism. The path to citizenship should not be easy. It should require sacrifice and effort of those that seek it. The cost could be assessed as a temporary or permanent income tax surcharge to those granted the privilege of lawful entry for the purpose of becoming an American, with no income tax surcharge exemption to offset the cost of educating the ignorant and training the unskilled applicants. I am all for work visas, especially for farm labor. Those have been handled very effectively for decades and that part is not broken. It's the free-for-all influx of undocumented people that range from poor people looking for a better life, to cartels, to terrorists and with the current administration there is no effort to monitor or manage the influx. People that cannot demonstrate their presence is for the benefit of America should be detained, incarcerated while their identity is verifed. If they are found to not be criminals, immediately deported. If they are found to be guilty of crimes, remain incarcerated and prosecuted to the full extent of the law with a mandatory maximum sentence, served consecutively with seperate felony charges for unlawful entry and domestic terrorism. The risk for those that enter unlawfully should be terrifying and strike tremendous fear and dread in their hearts and minds. For those that do it legally, the bounty should be plentiful and rewarding. My family is filled with mixed-race marriages and racism is not a point of discussion here. I love Mexico and I am of Native American descent. The issue is degradation of our nation's sovereignity and the need for the rule of law and intelligent immigation law enforcement.
-
Yeah, there has to come a point that it stops for your country and mine. And, playing the "asylum card" needs to be validated if it is not already. Simply saying it doesn't make it true, and they have figured out here that they are being allowed to get away with it by the people that want our borders open. I am in favor of militarizing our borders and using lethal force to stop illegal entry. They need to make arrangements on the other side. Once the details are worked out, then they can get red carpet treatment and a fast track to citizenship, while their presence is monitored and policed until they become a citizen. It should require English literacy and fluency and there should be no accommodation for those that cannot read and write English. The path to citizenship should include several years of mandatory military service and the completion of a high school education and trade education for those that have no trade or skills. I want legal immigration to flourish and I believe the diversity makes us a better nation, but the open borders merely brings the slum and scum to us. The crime and poverty that is ruining their countries is not our problem and yet we make it our problem by allowing it to enter here freely... which is absolutely insane. They need to check their "culture" at the border. If you want to be an American, you embrace the culture here, follow our laws,speak our language and contribute to America remaining a great and powerful nation.